Application Domain-specific Multi-objective Optimization
This project is a branch of Automatic Implementation of Secure Silicon (AISS) program which aims to increase the security of our nation’s semiconductor supply chain. Through a team of academic, government and industry partners, the AISS program aims to automate the process of incorporating scalable defense mechanisms into semiconductor chip designs, while allowing designers to explore chip economics versus security trade-offs based on the expected application.
AISS is composed of two teams of researchers and engineers who will explore the development of a novel design tool and IP ecosystem – which includes tool vendors, chip developers, and IP licensors – allowing defenses to be incorporated efficiently into chip designs. The expected AISS technologies could enable hardware developers to not only integrate the appropriate level of state-of-the-art security based on the target application, but also balance security with economic considerations like power consumption, die area, and performance.
The machine learning applications can be seen as the combinations of domain specific functions (DSFs). Each DSF has different computation requirements and therefore, the performance of DSFs depends on the underlying hardware. This project aims to optimize the performance of machine learning applications by finding the optimal hardware parameters at pre-silicon time. In order to do that, we are developing a framework that optimizes parameters of heterogeneous hardware for DSFs and gives pre-silicon design suggestions.
Project 1: Rapid PAS (Power, Area, Speed) Estimation of a Neural Network at the SoC level
When multiple neural network architectures are available, benchmarking can be time consuming to find optimal architecture. Moreover, if the target platform is in the pre-silicon phase, benchmarking can only be done with simulators which take a very long time. In this project, we are trying to estimate the inference delay and power consumption of neural networks without running them on computing platforms. In order to do this, we collect inference delay and power consumption data of different neural networks on different computing platforms and use this information to train machine learning algorithms.
Project 2: Intelligent Exploration for DSF-IP Mapping and Hardware Configurations for Optimal PAS Performance
Given a fine-grained DSF selection, a neural network can have an infinitely large number of DSF combinations. There are multiple optimal DSF combinations for different inference delay and power consumption requirements for a neural network. Since the state space is too large, it is hard to find optimal DSF combinations by exhaustive searching. Therefore, we are developing machine learning algorithms to find optimal DSF combinations for different inference delay and power consumption requirements.
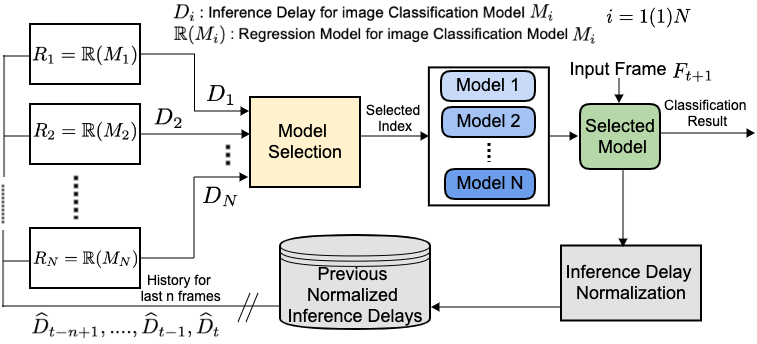
Project 3: Contention-aware Adaptive Model Selection for Neural Network Applications
In any computing system, unexpected contention creates unexpected delays. Unexpected delays are not wanted due to various reasons such as safety critical applications or quality of the applications. In this project, we are using the approximate nature of neural networks to isolate them from system contention. We are developing a framework to understand the system contention and select different neural network models for the same task. The framework’s aim is to stay under a certain inference delay threshold while maximizing the accuracy of the application.