Wireless AR/VR with Predictive AI and Edge Computing
Overview
Triggered by several head-mounted display (HMD) devices that have come to the market recently, such as Oculus Rift, HTC Vive, and Samsung Gear VR, significant interest has developed in virtual reality (VR) systems, experiences and applications. However, the current HMD devices are still very heavy and large, negatively affecting user experience. Moreover, current VR approaches perform rendering locally either on a mobile device tethered to an HMD, or on a computer/console tethered to the HMD.
In our projects, we discuss how to enable a truly portable and mobile VR/AR experience, with lightweight VR/AR glasses wirelessly connecting with edge/cloud computing devices that perform the rendering remotely. Our projects explore and develop techniques to enable three Degrees of Freedom (3DoF) and six Degrees of Freedom (6DoF) immersive experiences, with both natural videos and VR applications, with ultra-low latency requirements. Specifically, such immersive VR applications involve additional user activities -- user head rotation (for both 3DoF and 6DoF), and body movement (for 6DoF). While the acceptable response time to user control commands is 100-200ms (similar to first-person shooter games), a much lower latency of 10-20ms is needed with the user's head rotation and body movements.
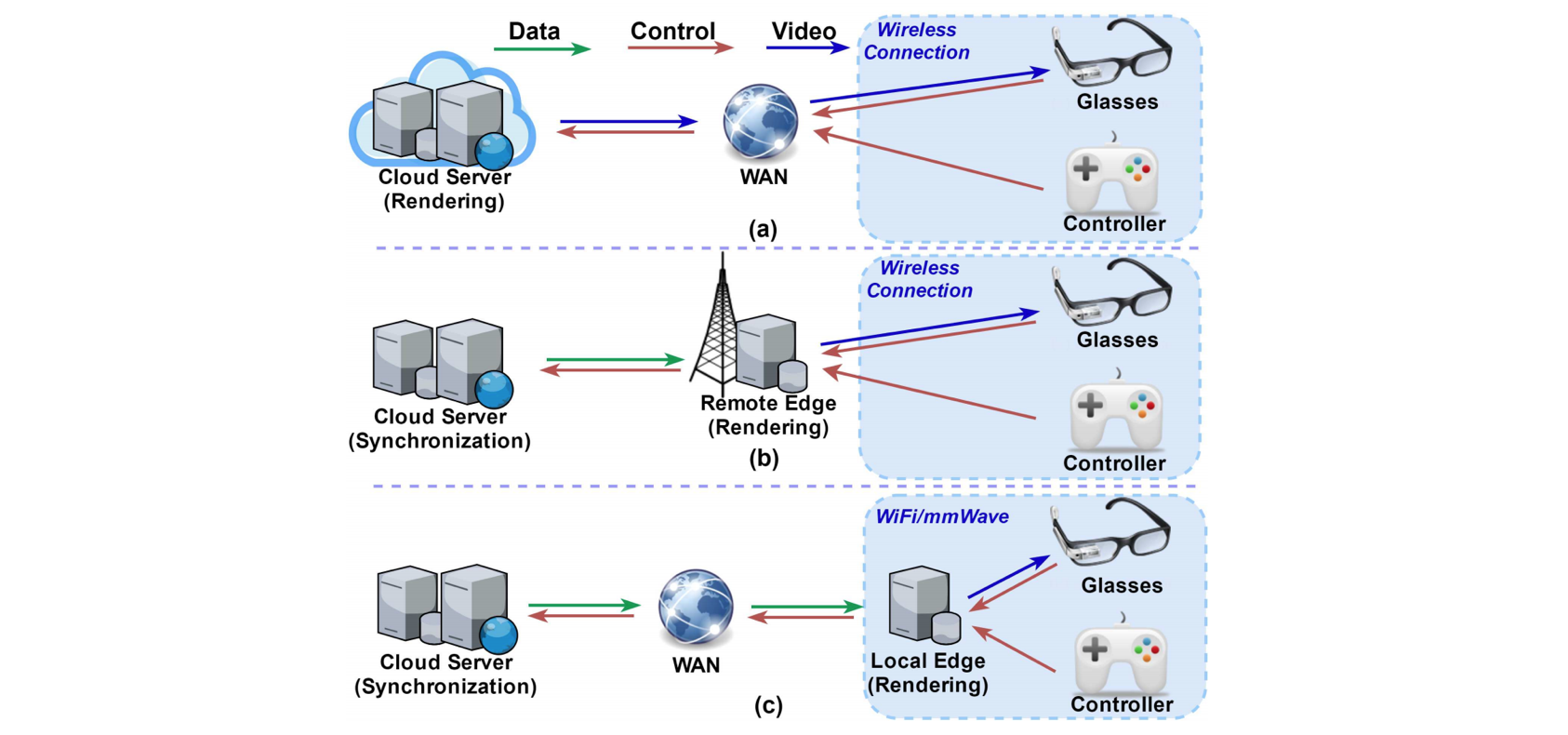
Since there are two main challenges of enabling wireless VR/AR with edge/cloud computing: ultra-high throughput needed, and ultra-low latency, our projects aim to find solutions for the above challenges. We summarize our three associated sub-projects below, and generally, three possible approaches to realize the wireless VR/AR with cloud/edge-based implementation are as follows: (a) rendering on the cloud server; (b) rendering on the remote edge server; (c) rendering on the local edge device.
Project 1: Multi-user Difference Encoding & Hybrid-casting to Address Ultra-high Bandwidth Requirement
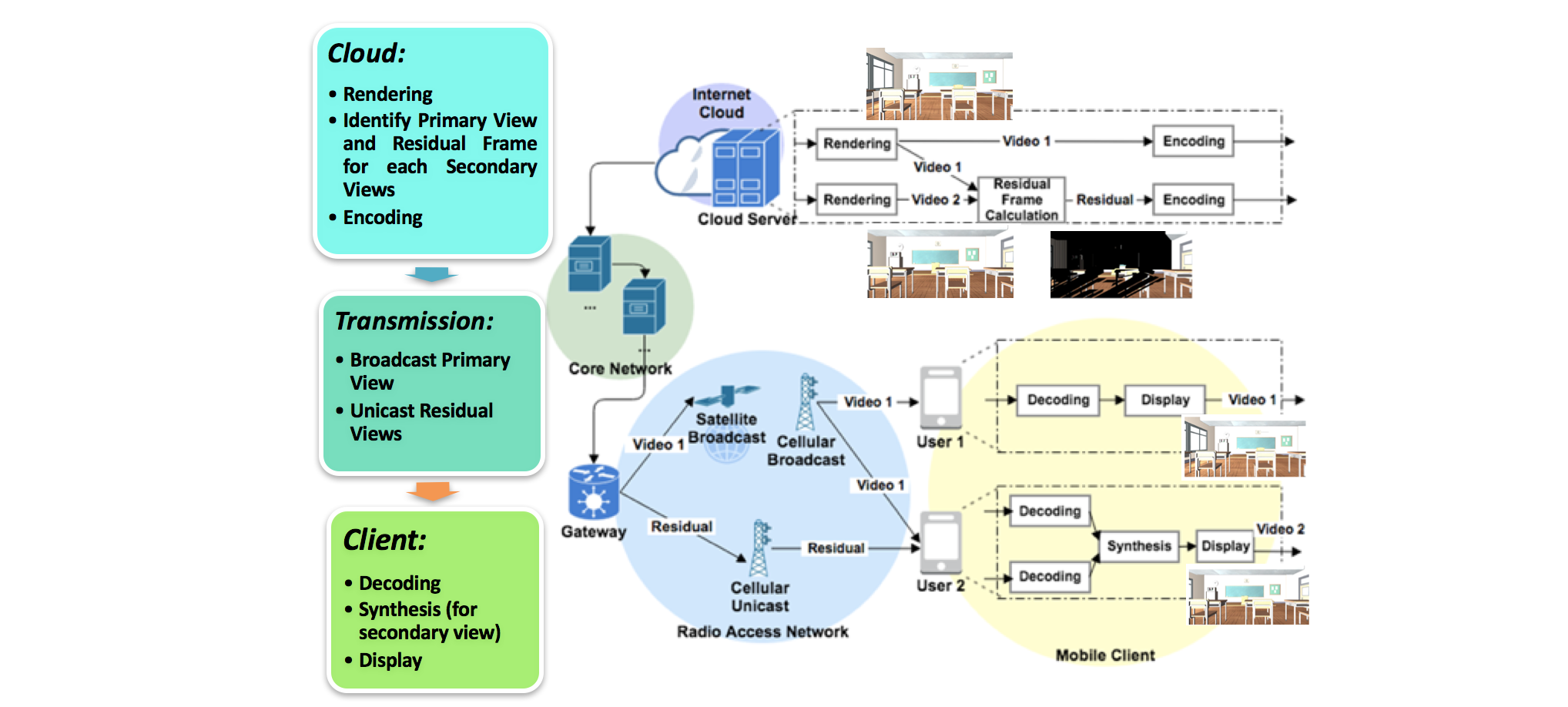
We investigate virtual space applications such as virtual classroom and virtual gallery, in which the scenes and activities are rendered in the cloud, with multiple views captured and streamed to each end device. A key challenge is the high bandwidth requirement to stream all the user views, leading to high operational cost and potential large delay in a bandwidth-restricted wireless network. In a multi-user streaming scenario, we propose a hybrid-cast approach to save bandwidth needed to transmit the multiple user views, without compromising view quality.
Specifically, we define the view of the user which shares the most common pixels with other users as the primary view, and the other views as secondary views. For each secondary view, we can calculate its residual view as the difference with the primary view, by extracting the common view from the secondary view. We term the above process of extracting common view and determining residual views multi-user encoding (MUE). Instead of unicasting the rendered video of each user, we can multicast/broadcast the primary view from the edge node to all the participating users and unicast each residual view to the corresponding secondary user.
We formulate the problem of minimizing the total bitrate needed to transmit the user views using hybrid-casting and describe our approach. A common view extraction approach and a smart grouping algorithm are proposed and developed to achieve our hybrid-cast approach. Simulation results show that the hybrid-cast approach can significantly reduce total bitrate and avoid congestion-related latency, compared to traditional cloud-based approach of transmitting all the views as individual unicast streams, hence addressing the bandwidth challenges of the cloud, with additional benefits in cost and delay.
Project 2: Predictive View Generation to Enable Mobile 360-degree and VR Experiences
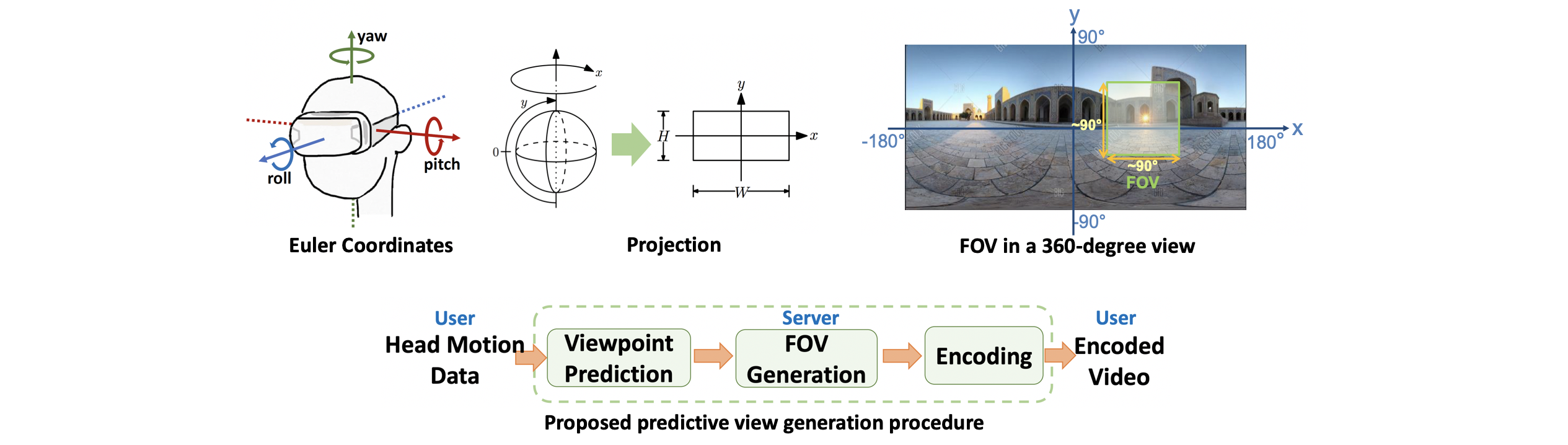
As 360-degree videos and VR applications become popular for consumer and enterprise use cases, the desire to enable truly mobile experiences also increases. Delivering 360-degree videos and cloud/edge-based VR applications require ultra-high bandwidth and ultra-low latency, challenging to achieve with mobile networks. A common approach to reduce bandwidth is streaming only the field of view (FOV). However, extracting and transmitting the FOV in response to user head motion can add high latency, adversely affecting user experience. In this project, we propose a predictive view generation approach, where only the predicted view is extracted (for 360-degree video) or rendered (in case of VR) and transmitted in advance, leading to a simultaneous reduction in bandwidth and latency.
The view generation method is based on a deep-learning-based viewpoint prediction model we develop, which uses past head motions to predict where a user will be looking in the 360-degree view. Using a very large dataset consisting of head motion traces from over 36,000 viewers for nineteen 360-degree/VR videos, we validate the ability of our viewpoint prediction model and predictive view generation method to offer very high accuracy while simultaneously significantly reducing bandwidth.
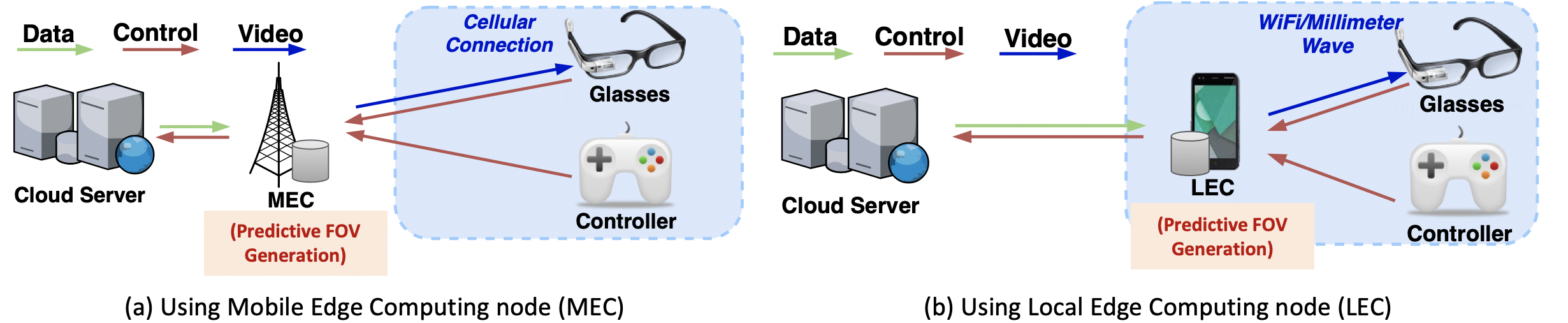
Specifically, the system overview is shown below. User’s head motion as well as other controlling commands will be sent to the edge device, which performs viewpoint prediction and predictive rendering. The edge device can be either a Mobile Edge Computing node (MEC) in the mobile radio access or core network (Fig. (a)), or a Local Edge Computing node (LEC) located in the user premises or even his/her mobile device (Fig. (b)). Based on past few seconds of head motion and control data received from the user and using the viewpoint prediction model developed, the edge device will perform predictive view generation, and stream the predicted FOV to the user HMD in advance.
Project 3: Enabling Ultra-low Latency Immersive Mobile Experiences with Viewpoint Prediction
For 3DoF and 6DoF VR applications, the ultra-low latency requirement with user's head rotation and body movements can be very challenging to meet, as new video needs to be rendered in response to user's head and body motions, and then displayed on the HMD. Moreover, if a truly wireless experience is desired, the video needs to be rendered and streamed wirelessly from a local/edge computing device further adding to the delay. In this project, we focus on techniques to ensure the ultra-low latency requirement of head motion as well as body motion.
One possible way of address the ultra-low latency challenge is always pre-fetching the entire rendered or natural video to the user device or edge node; when head motion happens, the corresponding Field of View (FOV) can be displayed almost immediately, thus significantly reducing latency. However, pre-fetching the entire view consumes ultra-high bandwidth (i.e. 4 times more than regular videos). Moreover, for 6DoF, since the user location is not known in advance, it is not clear what would be the right video to render and transmit in advance. Therefore, in this project, we propose a novel approach of pre-fetching the content within a predicted view frustum based on head and body motion prediction of the user. Streaming the above partial content is expected to consume much less bandwidth than the complete original content, and can be transmitted with high quality in advance, leading to satisfaction of both latency and high quality of experience (QoE).

Associated Publications